Common Voice από τη Mozilla: Το άμεσο μέλλον της αλληλεπίδρασης μεταξύ ανθρώπου-μηχανής έγκειται στον έλεγχο φωνής με τα έξυπνα ηχεία, τις οικιακές συσκευές και τα τηλέφωνα που ακούν εντολές για να τις κάνουν πράξεις.
Ωστόσο, οι φωνητικοί βοηθοί, της Alexa της Amazon ή το Siri της Apple, αντιπροσωπεύουν τους συντριπτικά λευκούς, αρσενικούς προγραμματιστές που φαίνεται να έχουν φυλετικές προκαταλήψεις.
Για παράδειγμα, εάν έχετε κάποια παράξενη προφορά, ή η μητρική σας γλώσσα δεν είναι τα αγγλικά, οι πιθανότητες είναι ότι δεν θα λάβετε ποτέ αυτό που ζητάτε.
Για να λύσει αυτό το θέμα, η Mozilla, μια κοινότητα ελεύθερου λογισμικού, δημιούργησε το “Common Voice” το 2017, ένα εργαλείο που συγκεντρώνει φωνές σαν σύνολα δεδομένων για να δημιουργήσει ένα διαφορετικό AI που αντιπροσωπεύει τον παγκόσμιο πληθυσμό, και όχι μόνο τη δύση.

Το Common Voice λειτουργεί διαθέτοντας δημόσια ένα συνεχώς αυξανόμενο σύνολο δεδομένων. Έτσι κάθε εταιρεία να μπορεί να χρησιμοποιήσει τα δεδομένα αυτά για έρευνα, να δημιουργήσει και να εκπαιδεύσει τις δικές της εφαρμογές φωνής, βελτιώνοντας τη φωνητική αναγνώριση για όλους ανεξάρτητα από τη γλώσσα, το φύλο, την ηλικία ή την προφορά.
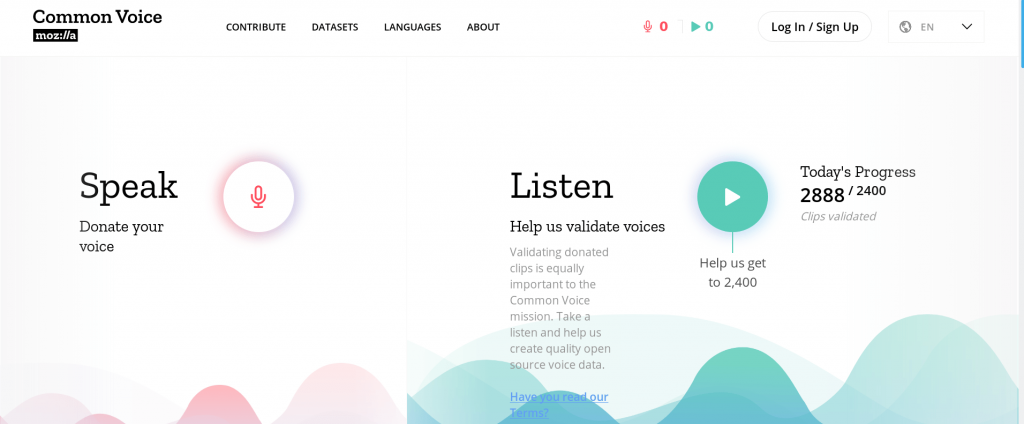
Επί του παρόντος, υπάρχουν περισσότερες από 2.400 ώρες φωνητικών δεδομένων και 29 γλώσσες (Αγγλικά, Γαλλικά, Γερμανικά, Κινέζικα, και Kabyle.)
“Οι υπάρχουσες υπηρεσίες αναγνώρισης ομιλίας είναι διαθέσιμες μόνο σε γλώσσες που είναι οικονομικά κερδοφόρες”, δήλωσε στο TNW ο Kelly Davis, επικεφαλής της Μηχανικής Μάθησης της Mozilla.
Η ομιλία αρχίζει να γίνεται ο προτιμώμενος τρόπος αλληλεπίδρασης με την τεχνολογία και σε αυτό συνέβαλε η ανάπτυξη υπηρεσιών νέων από την Amazon (Alexa) και την Google με το Google Assistant.
Αυτοί οι φωνητικοί βοηθοί έχουν ανατρέψει τον τρόπο με τον οποίο επικοινωνούμε με την τεχνολογία, ωστόσο, η καινοτόμος δυναμική αυτής της τεχνολογίας είναι ευρέως ανεκμετάλλευτη, επειδή οι προγραμματιστές, οι ερευνητές και οι νεοσύστατες επιχειρήσεις σε όλο τον κόσμο που ασχολούνται με την τεχνολογία αναγνώρισης φωνής αντιμετωπίζουν ένα πρόβλημα: την αδυναμία παροχής φωνητικών δεδομένων σε πολλές γλώσσες για την εκπαίδευση των speech-to-text engines “, εξηγεί ο Davis.
Παρόλο που ο Davis πιστεύει ότι το AI έχει αρχίσει να βελτιώνεται, αν και αργά, απέχουν πολύ από το σημείο που πρέπει να φτάσουν. Στα τέλη του 2017, η Amazon πρόσθεσε μια ινδο-αγγλική προφορά στην Alexa, επιτρέποντάς της να προφέρει ινδικές φράσεις και να καταλάβει μερικές ινδικές αποχρώσεις φωνής.
Όμως η φωνητική βοηθός εξακολουθεί να εξυπηρετεί σε μεγάλο βαθμό τη δύση, αφού έξι από τις επτά γλώσσες που χρησιμοποιεί είναι ευρωπαϊκές.
Στις αρχές του 2018, η Google ανακοίνωσε την υποστήριξη για Hindi στον φωνητικό βοηθό της, αλλά η δυνατότητα περιοριζόταν σε μερικά ερωτήματα. Λίγους μήνες μετά την αρχική κυκλοφορία η Google ενημέρωσε το χαρακτηριστικό ώστε ο Google Assistant να μπορεί πλέον να κάνει συνομιλίες σε Hindi – την τρίτη περισσότερο ομιλούμενη γλώσσα στον κόσμο.
“Σε μεγάλο βαθμό, οι προσπάθειες για την αντιμετώπιση του χάσματος του AI έχουν πέσει σε μη εταιρικά χέρια”, ανέφερε ο ο Davis.
Για παράδειγμα, το project Black In AI, που αναζητεί τρόπους για την ενσωμάτωση φωνητικών χαρακτηριστικών ανθρώπων που δεν κατοικούν στην Δύση, στο AI, ξεκίνησε από τους πρώην εργαζόμενους στο Google το 2017.
Ωστόσο, δεν ξεκίνησε σαν μια επίσημη επέκταση του έργου της εταιρείας. Ξεκίνησε για να αντιμετωπίσουν αυτό που είδαν σαν πρωτεύουσα ανάγκη στην κοινότητα.
Ο Davis υποστηρίζει ότι αυτή τη στιγμή επωφελούνται ελάχιστοι από την τεχνολογία φωνητικής αναγνώρισης.
“Σκεφτείτε πώς η αναγνώριση ομιλίας θα μπορούσε να χρησιμοποιηθεί από τους ομιλητές της μειονοτικών γλωσσών για να επιτρέψει σε περισσότερους ανθρώπους να έχουν πρόσβαση στην τεχνολογία και τις υπηρεσίες που μπορεί να προσφέρει το διαδίκτυο, ακόμη και αν δεν έμαθαν ποτέ να διαβάζουν.”
“Το ίδιο ισχύει και για άτομα με προβλήματα όρασης ή άτομα με ειδικές ανάγκες, αλλά η σημερινή αγορά δεν φαίνεται να μπορεί να τους βοηθήσει”.
Το Common Voice project ευελπιστεί να επιταχύνει τη διαδικασία συλλογής δεδομένων σε όλες τις γλώσσες και από όλο τον κόσμο, ανεξάρτητα από την προφορά, το φύλο ή την ηλικία.
“Κάνοντας αυτά τα δεδομένα διαθέσιμα – και αναπτύσσοντας έναν μηχανισμό αναγνώρισης ομιλίας, (το project Deep Speech) μπορούμε να ενδυναμώσουμε τους επιχειρηματίες και τις κοινότητες να αντιμετωπίσουν τα υπάρχοντα χάσματα”, πρόσθεσε ο Davis.
ΑΝ θέλετε να βοηθήσετε στη διαφοροποίηση της φωνητικής αναγνώρισης του Common Voice project, κάντε μια εγγραφή και προσπαθήστε να διαβάσετε προτάσεις ή να ακούσετε άλλες εγγραφές. Μετά, απλά επαληθεύστε αν είναι ακριβείς.
__________________________
- Microsoft: έλεγχος ταυτότητας πολλαπλών παραγόντων προστασία κατά 99,9%
- Windows 10 19H2 ξεκίνησαν οι δοκιμές του Update System
- Windows 7 εκτεταμένη υποστήριξη δωρεάν για ορισμένους

“Οι υπάρχουσες υπηρεσίες αναγνώρισης ομιλίας είναι διαθέσιμες μόνο σε γλώσσες που είναι οικονομικά κερδοφόρες”
ΕΝΤΕΛΩΣ ΑΝΤΙΡΑΤΣΙΤΣΙΚΟ…